OpenAI 发布了 GPT-5.5,GPT-5 系列迄今为止最大的一次更新。
这次的核心变化用一句话概括:用更少的 token,干更难的活。编程、知识工作、科学研究三个方向全面提升,API 定价 $5/$30(每百万 token),已经向 ChatGPT Plus 用户开放。
下面把 GPT-5.5 的能力、价格、和谁比怎么选,一次说清楚。
相关教程推荐:
- GPT-5.6 已发布!查看 GPT-5.6 正式发布:如何使用 GPT-5.6 Sol/Terra/Luna — 使用教程与 API 价格
- GPT-5.6 已发布!查看 GPT-5.6 发布:国内用户如何充值升级第一时间体验
- 还没开通 Plus?先看 ChatGPT Plus 国内充值/升级与支付教程
- 想了解 ChatGPT Pro 两档计划?查看 ChatGPT Pro 两档区别与升级攻略
- 想用 AI 生成图片?看看 GPT-Image-2 提示词大全
GPT-5.5 是什么:GPT-5 系列迄今最大更新
GPT-5.5 是 OpenAI 在 2026 年 4 月 23 日发布的新一代旗舰模型。
跟之前几次发布不一样,这次 OpenAI 的主题不是「最强智能」,而是「为真实工作而生的一类新智能」。这个措辞上的变化挺值得注意的——OpenAI 不再强调跑分多高、多聪明,开始把重心放在「实际干活」上。
 OpenAI GPT-5.5 发布官方公告
OpenAI GPT-5.5 发布官方公告
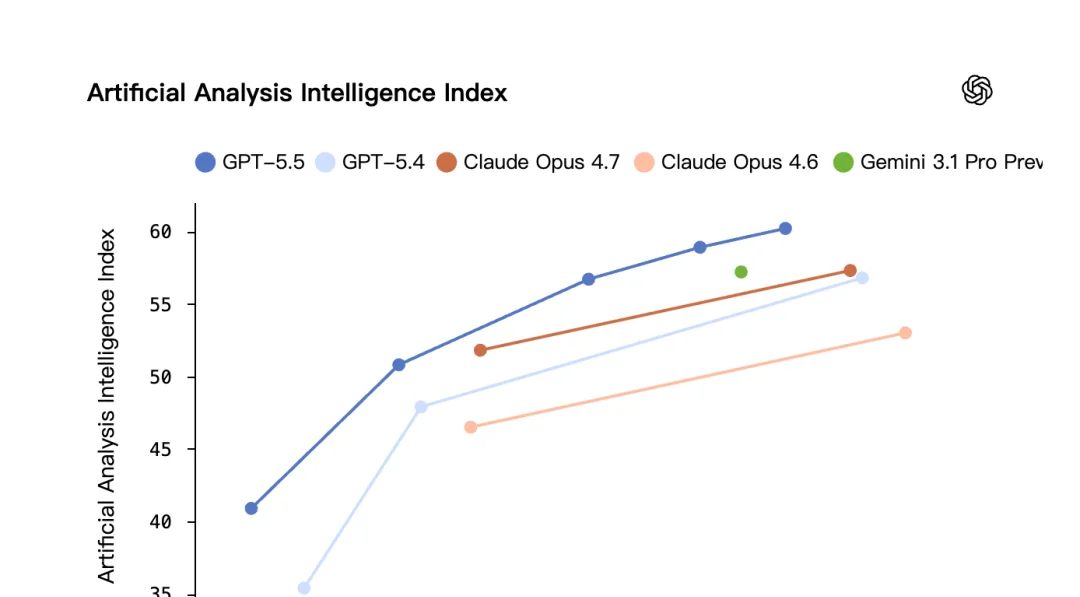
在第三方评测平台 Artificial Analysis 的 Coding Agent Index 上,GPT-5.5 达到了最高智能水平,而成本只有同级别竞品的一半。
 GPT-5.5 在 Coding Agent Index 上的性能与成本对比
GPT-5.5 在 Coding Agent Index 上的性能与成本对比
简单说,GPT-5.5 走的是「性价比路线」——不一定每项都是第一名,但综合成本和能力来看,很难找到更划算的选择。
GPT-5.5 已向 Plus 用户开放,支付宝微信即可充值升级
GPT-5.5 和 GPT-5.4 有什么区别:核心 Benchmark 对比
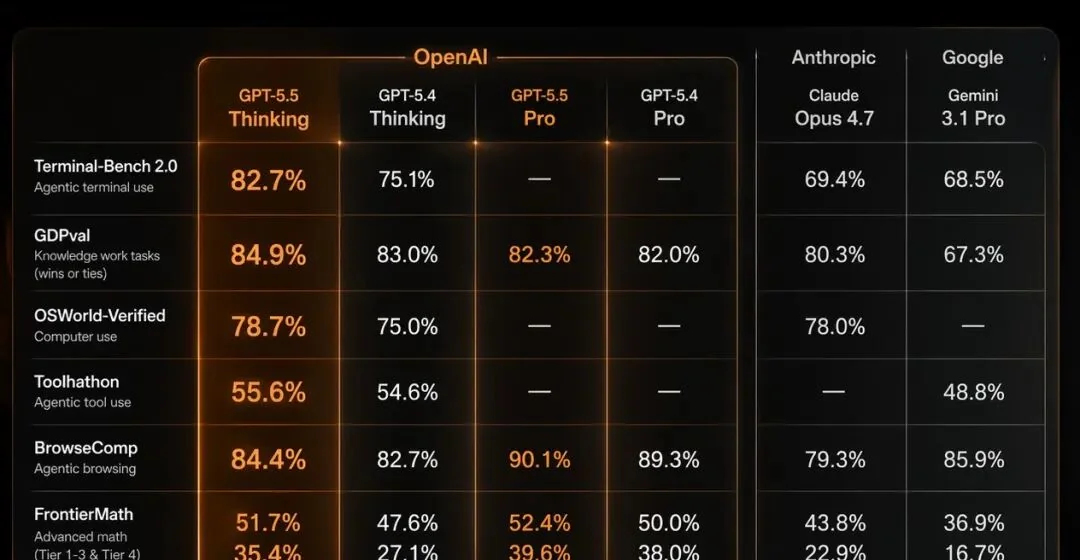
OpenAI 放出了一张 9 项核心指标的对比表,横向对比了 GPT-5.5、GPT-5.4、GPT-5.5 Pro、GPT-5.4 Pro、Claude Opus 4.7 和 Gemini 3.1 Pro。
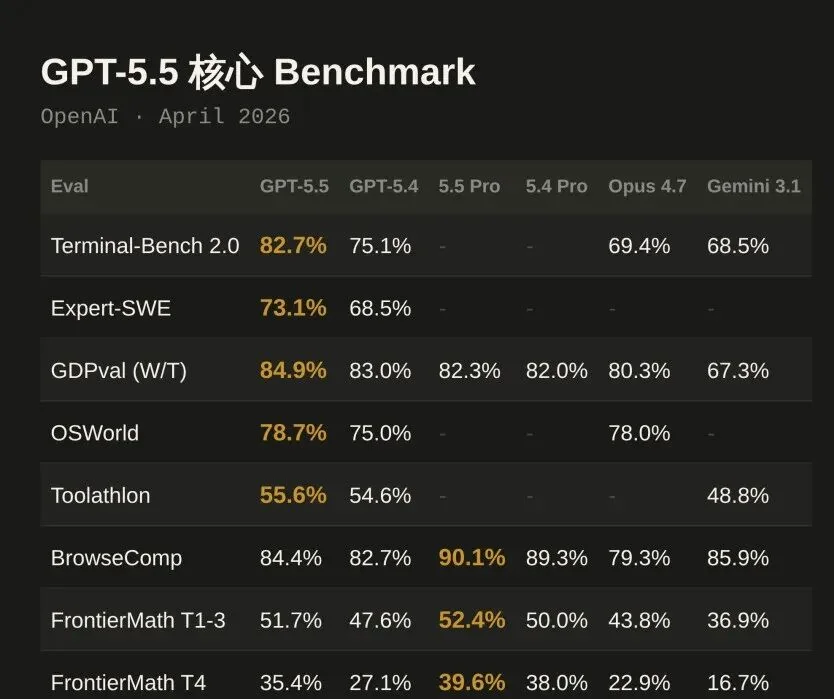 GPT-5.5 九项核心 Benchmark 评测对比表
GPT-5.5 九项核心 Benchmark 评测对比表
核心数据汇总:
| 评测项目 | GPT-5.5 | GPT-5.4 | 提升幅度 |
|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 75.1% | +7.6% |
| SWE-Bench Pro | 58.6% | 57.7% | +0.9% |
| Expert-SWE | 73.1% | 68.5% | +4.6% |
| GDPval | 84.9% | 83.0% | +1.9% |
| OSWorld-Verified | 78.7% | 75.0% | +3.7% |
| Tau2-bench Telecom | 98.0% | 92.8% | +5.2% |
| GeneBench | 25.0% | 19.0% | +6.0% |
| BixBench | 80.5% | 74.0% | +6.5% |
从数据看,GPT-5.5 在编程、知识工作和科研三个方向上都有提升,幅度最大的是 Terminal-Bench(+7.6%)和 BixBench(+6.5%)。
不过要注意,这不是「全面碾压」式的升级。SWE-Bench Pro 只涨了不到 1 个点,GDPval 也只多了 1.9%。GPT-5.5 的提升更像是「稳步前进」,而不是「代际飞跃」。
GPT-5.5 编程能力怎么样:Coding Benchmark 详解
编程是这次提升最明显的方向。三个核心编程评测的表现:
Terminal-Bench 2.0 测的是复杂命令行工作流。GPT-5.5 拿了 82.7%,GPT-5.4 是 75.1%,Claude Opus 4.7 只有 69.4%。这项评测 GPT-5.5 领先幅度最大,说明在长流程终端操作上,GPT-5.5 确实强了一截。
SWE-Bench Pro 测的是真实 GitHub issue 解决能力。GPT-5.5 拿了 58.6%,GPT-5.4 是 57.7%。提升不大,但要注意:Claude Opus 4.7 在这项上报了 64.3%,不过 Anthropic 自己承认部分问题存在记忆化,实际差距可能没那么大。
Expert-SWE 是 OpenAI 内部的长周期编码任务评测,中位人类完成时间 20 小时。GPT-5.5 拿了 73.1%,GPT-5.4 是 68.5%。这个提升对重度开发者来说比较有意义。
 GPT-5.5 编程能力 Benchmark 评测数据
GPT-5.5 编程能力 Benchmark 评测数据
在 Codex 里,GPT-5.5 可以接手从实现、重构到调试、测试的完整工程工作。上下文窗口达到 400K token,处理大型项目更从容。如果你还没用过 Codex,可以先看看 Codex App 上手指南。
GPT-5.5 知识工作能力:日常办公与真实场景测试
编程之外,GPT-5.5 在日常办公和知识工作上的提升同样明显。OpenAI 这次推出的几个评测都很接地气,不是纯学术跑分,而是模拟真实的工作场景。
GDPval 覆盖 44 个职业的知识工作测试,衡量的是「你坐在电脑前一天能干多少活」。GPT-5.5 胜出或平手率 84.9%,GPT-5.4 是 83.0%,Claude Opus 4.7 是 80.3%。
OSWorld-Verified 更贴近真实电脑操作——模型要看界面、识别按钮、切窗口、调用工具、走多步流程。GPT-5.5 拿了 78.7%,GPT-5.4 是 75.0%。
Tau2-bench Telecom 测的是电信场景里的复杂客服工作流,无 prompt 调优。GPT-5.5 拿了 98.0%,几乎完美。GPT-5.4 是 92.8%。
 GPT-5.5 知识工作能力 GDPval 与 OSWorld 评测结果
GPT-5.5 知识工作能力 GDPval 与 OSWorld 评测结果
OpenAI 内部怎么用 GPT-5.5
OpenAI 自己公司超过 85% 的员工每周都在用 Codex,覆盖工程、财务、市场、公关、数据科学、产品管理。他们公开了几个内部用例:
- 财务团队用 Codex 审了 24,771 份 K-1 税表,共 71,637 页,比去年提前两周完成
- GTM 团队自动生成周报,每周省 5-10 小时
没有「AGI 来了」这样的大词,全是实打实的工作量减少。但这些场景才是企业真正会买单的。
GPT-5.5 科学研究能力:GeneBench 与 Ramsey 数新证明
科研方向的提升也值得关注。
GeneBench 是 OpenAI 新推出的评测,测试多阶段遗传学和定量生物学数据分析。这些任务通常对应科研专家几天到几周的工作量。GPT-5.5 得分 25.0%,GPT-5.4 是 19.0%,GPT-5.5 Pro 达到 33.2%。
BixBench(真实生物信息学和数据分析 benchmark):GPT-5.5 得分 80.5%,GPT-5.4 是 74.0%,提升了 6.5 个百分点。
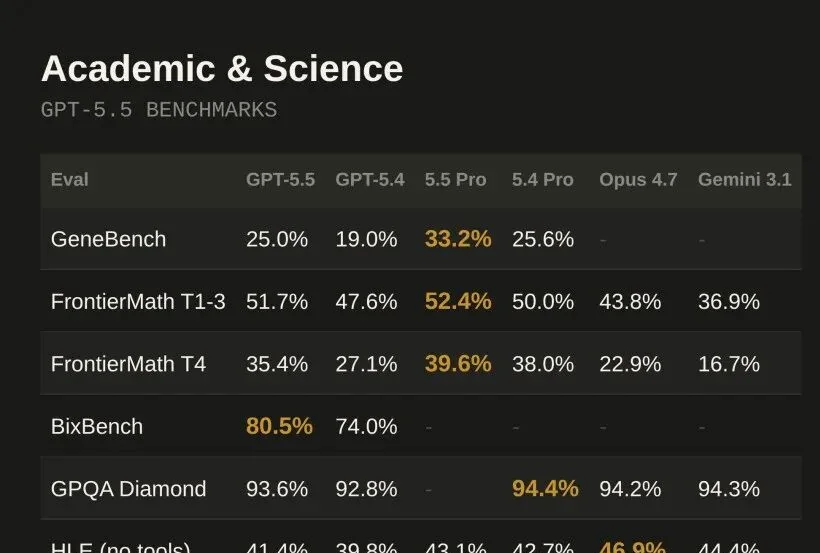 GPT-5.5 科学研究 GeneBench 与 BixBench 评测数据
GPT-5.5 科学研究 GeneBench 与 BixBench 评测数据
Ramsey 数新证明
GPT-5.5 的内部版本配合自定义工具链,发现了关于 Ramsey 数的一个新证明。Ramsey 数是组合数学的核心对象,研究结果稀少且技术难度极高。这个证明后来在 Lean 中完成了形式化验证。
 GPT-5.5 发现 Ramsey 数新证明的数学突破
GPT-5.5 发现 Ramsey 数新证明的数学突破
对于科研人员来说,GeneBench 和 BixBench 的提升意味着 GPT-5.5 在处理复杂数据分析任务时更可靠。而 Ramsey 数的证明则说明,在配合合适的工具链的情况下,GPT-5.5 有能力产出有学术价值的成果。
GPT-5.5 推理效率:用更少的 Token 干更难的活
GPT-5.5 模型更大、能力更强,但实际延迟和 GPT-5.4 基本持平。
这一点很关键。一个模型如果只是变聪明,但每次调用更慢、更贵、更不稳定,它就很难进入真正的大规模业务流程。GPT-5.5 做到了「变强但不变慢」。
具体怎么做到的?OpenAI 用 Codex 分析了数周的生产流量数据,写了自定义的启发式分区算法来优化 GPU 负载均衡。这一项改进就让 token 生成速度提升了超过 20%。
 GPT-5.5 推理效率对比 Token 生成速度提升
GPT-5.5 推理效率对比 Token 生成速度提升
OpenAI 在 Codex 里实测发现,GPT-5.5 对大多数用户来说,实际消耗的 token 比 GPT-5.4 更少。模型变强了,用量反而下降了。
GPT-5.5 和 Claude Opus 4.7 对比:选哪个更值
这是很多人关心的问题。直接看数据:
GPT-5.5 在多项指标上领先 Claude Opus 4.7。但如果对标 Anthropic 最强的 Claude Mythos,情况就不一样了——8 项核心 benchmark,Mythos 领先 7 项。GPT-5.5 只在 Terminal-Bench 2.0 上赢了 0.7 个点。
不过价格差距很大:
| 对比项 | GPT-5.5 | Claude Mythos |
|---|---|---|
| 输入价格 | $5/M tokens | $25/M tokens |
| 输出价格 | $30/M tokens | $125/M tokens |
| 价格倍数 | 1x | 约 5x |
GPT-5.5 价格只有 Mythos 的五分之一。
怎么选?看你的需求:
- 追求极限能力:Claude Mythos 在大多数学术和编程基准上确实更强,但价格贵 5 倍
- 追求性价比和稳定性:GPT-5.5 不一定最聪明,但够用、便宜、快,适合大规模接入业务流程
- 日常 ChatGPT 使用:GPT-5.5 对 Plus 用户直接可用,和 Claude Opus 4.7 比差距不大,体验提升明显
GPT-5.5 也有明显短板:SWE-Bench Pro 上 Claude Opus 4.7 更强(64.3% vs 58.6%);MCP Atlas 上 Claude Opus 4.7(79.1%)和 Gemini 3.1 Pro(78.2%)均高于 GPT-5.5(75.3%);长上下文 256K 以上,Claude Opus 4.7 在部分指标上仍有优势。
GPT-5.5 价格多少:API 定价与订阅方案
ChatGPT 订阅怎么用 GPT-5.5
GPT-5.5 Thinking 面向 Plus、Pro、Business、Enterprise 用户开放。GPT-5.5 Pro(更强的推理版本)面向 Pro、Business、Enterprise 用户开放。
如果你是 Plus 用户,直接就能在 ChatGPT 里使用 GPT-5.5。如果你还没升级 Plus,可以参考 ChatGPT Plus 国内充值教程。
想了解 Pro 两档计划的区别和升级方式,可以看 ChatGPT Pro 值得买吗?5x 和 20x 两档区别。
Codex 中的 GPT-5.5
GPT-5.5 面向 Plus、Pro、Business、Enterprise、Edu、Go 计划开放,上下文窗口 400K token。Fast 模式 token 生成速度提升 1.5 倍,成本是标准模式的 2.5 倍。
不同订阅级别的 Codex 额度差异比较大,具体可以参考 Codex 额度详解与省流攻略。
API 定价
 GPT-5.5 API 定价方案与 GPT-5.4 对比
GPT-5.5 API 定价方案与 GPT-5.4 对比
| 模型 | 输入价格 | 输出价格 | 上下文窗口 |
|---|---|---|---|
| gpt-5.5 | $5/M tokens | $30/M tokens | 1M |
| gpt-5.5-pro | $30/M tokens | $180/M tokens | — |
| Batch / Flex | 标准价的一半 | 标准价的一半 | — |
| Priority | 标准价的 2.5 倍 | 标准价的 2.5 倍 | — |
GPT-5.5 单价比 GPT-5.4 高了约 3 倍。但因为 token 效率更高,实际总成本不一定比 GPT-5.4 贵。OpenAI 说在 Codex 里大多数用户的 token 消耗反而更少。
GPT-5.5 值得升级吗:不同用户的推荐方案
这取决于你的使用场景。
ChatGPT Plus 用户:GPT-5.5 已经直接可用了,不需要额外操作。日常使用会感受到编程和知识工作方面的提升,推荐直接切换体验。
ChatGPT Pro 用户:GPT-5.5 Pro 在业务、法律、教育、数据科学方向上比 GPT-5.4 Pro 更全面、更准确。如果你是重度用户,升级到 GPT-5.5 Pro 是值得的。关于 Pro 的编程体验和实际限制,可以参考 ChatGPT Pro 编程体验与使用限制。
API 开发者:价格涨了 3 倍但 token 效率更高,需要根据自己的场景实测。建议用 Batch/Flex 模式降低成本。对于编程类 Agent 场景,GPT-5.5 在 Terminal-Bench 和 Expert-SWE 上的提升比较显著。
观望用户:如果你主要用 ChatGPT 聊天、问问题,GPT-5.5 和 GPT-5.4 的体感差异可能不大。但如果你经常用 Codex 写代码或者做数据分析,GPT-5.5 的提升会比较明显。
相关推荐
- GPT-5.6 发布:国内用户如何充值升级第一时间体验 — GPT-5.6 三档模型与 Plus/Pro 充值升级指南
- GPT-5.6 的 Token 用得太快?3 个原因和 2 个解决办法 — Token 消耗过快的原因与省流技巧
- ChatGPT Plus 国内充值/升级与支付教程 — 国内用户升级 Plus 的完整指南
- ChatGPT Pro 值得买吗?5x 和 20x 两档区别 — Pro 两档计划的详细对比
- ChatGPT Pro 编程体验与使用限制 — Pro 在编程场景下的实测体验
- Codex App 上手指南 — 从安装到使用 Skills 的完整教程
- GPT-Image-2 提示词大全 — 50+ ChatGPT 中文生图提示词实测案例